Working with Producers and Consumers#
Working with Producers#
Written in any language or can be initiated throught the command line. With no key for partitioning stratergy the
producer will use a round-robing strategy. Alternative the default strategy is hash(key) % number_of_partitions.
Messages of the same key land in order.
The standard producer (in Java) contains of several fundamental blocks. This includes the configuration with
information about the cluster. Then you create the producer using the KafkaProducer passing the configuration. Then a
part which produces data and sends it to the producer, using the class ProducerRecord with the topic of interest.
See figure below.
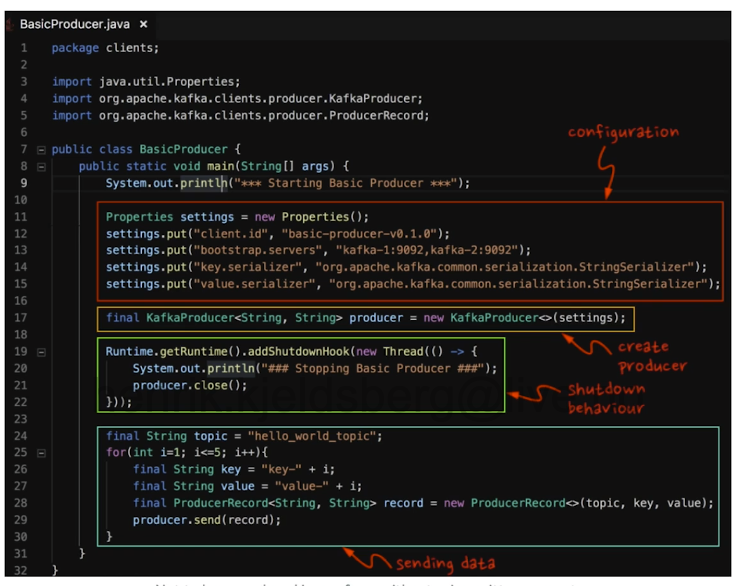
Fig. 2 A representative producer in Java.#
Building a Producer in Java#
Data can be published to data though Kafka’s Java Producer API. A producer is created using the KafkaProducer
class:
Producer<String, String> producer = new KafkaProducer<>(props);
// Send one record/log
int i = 0;
ProducerRecord producer = new ProducerRecord<>("test_count", partition, "count",Integer.toString(i));
producer.send(record);
producer.close();
Producer design and reliability#
What happends when you call Send()? First, it goes through serialization, turning it into the bytes. This is
passed to the partitioner checking for a key, alternatively hashing it and deciding which patition it will be
written to.
What happens in the broker?
If
NONE(Acks 0) sends it, we have no info what happened in the broker. Lowest latency.If
LEADER(Acks 1) sends the data, and waits for acknowledgement from broker. Does not wait for replication.If
ALL(Acks -1) means the leader and all its replicas have sent data. Safest but produces more latency.
Three processes can happen: “At most once” (may lose data), “At least once” (everything goes through, may be doubled), and “Exactly once” (one to one).
At least once (Default): Does not result in data loss, processes one or more times, and may result in duplicates
At most once: Can result in data loss, processes once (or never), but has no duplicates. Useful for checking traffic.
Exactly once: Does not result in data loss, processes exactly once, and does not produce duplicates
This semantic prevents duplication, Handles failures gracefully, and is a strong transactional guarantees for Kafka.
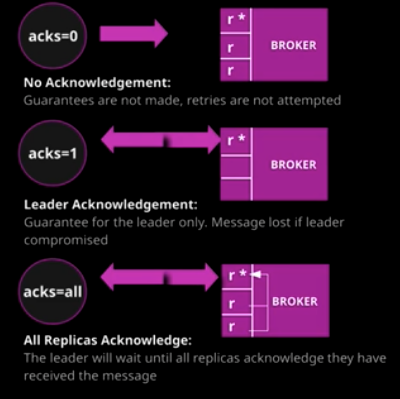
Fig. 3 Different types of Acknowledgements in Kafka (acks).#
Working with Consumers#
A consumer pull messages from 1, …, \(n\) topics. The consumer offset is also stored in memory, and is stored in a special topic: consumer offset which keeps track of the consumers “position”. Consumers can also belong to a consumer group.
For the consumder (here in C#), start the consumer file with some configuration. Then initialize some event-handlers,
which handles messages and potential errors. The consumer is initialized using the Consumer class, with a
function Subscribe where the topic of interest needs to be specified (multiple topics can be subscribed to).
A while (true)-loop is then initiated to Poll (pull, consume) the date from the Kafka cluster. See figure below.
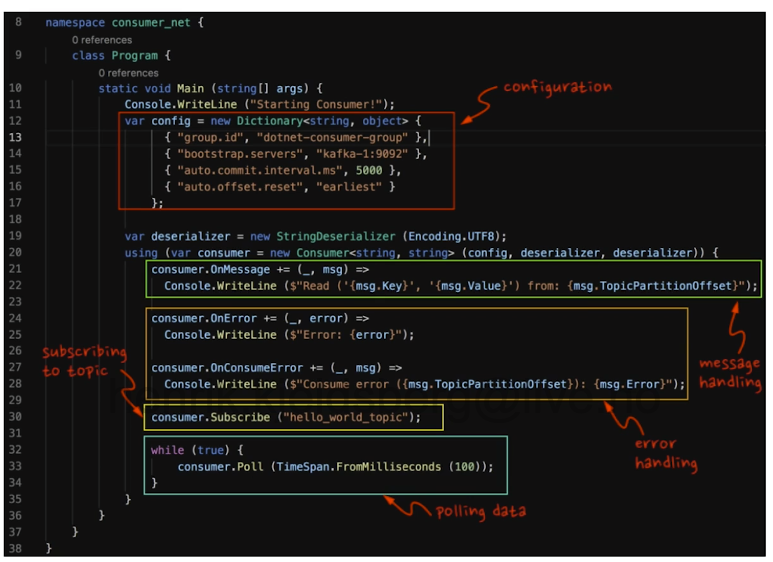
Fig. 4 A representative consumer in C#.#
Building a Consumer in Java#
A consumer can be built though the Java Consumer API. The KafkaConsumer class will handle interaction between the
Java code and Kafka:
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// Subscribe to topic(s)
consumer.subscribe(Arrays.asList("test_topic1", "test_topic2"));
// Fetch records:
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
// Perform some operations on records..
consumer.commitSync();
Consumer groups#
Consider two producers, producing two unique topics. Then two consumers can consume both topics. How is this assigned when the consumers have the same group ID? The consumers are doing its best at allocating the partitions. What if we scale the consumer? Then the partition reassigns partitions automaticalyl. If something failes, a new rebalance happens automatically. However, the consumer API does not consider state.
Integrity#
The consumer goes to the broker through a polling event. When consumer is reading data and there are too many threads – results in a concurrent modification excetion. Insted it is recommended with one consumer per thread. Through polling, the consumer sends/commits an offset. This will give information to the consumer about where to pick up, based on the last used offset, either form itself or other consumers consuming. In contrast, a committed message is an acknowledgement sent by the leader replica, confirming that the message has been committed.
A consumer can read an offset, but never finish – this is an incomplete message, and is considered a lost message. If
offset expires or does not exist, the consumer’s action may be controlled by the auto.offset.reset configuration
variable – set to earliest, lastest, none or anything; resetting the offset or throwing an exception.
Other consumer settings:
enable.auto.commit– letting the consumer chose when to commit offsets or alternatively manually in the code.auto.commit.interval.ms– Tied to variable above. If automatic, this determines how frequent the commit is. Default:5ms