Kafka Basics#
Data is described by logs or topics. An alternative way to store data as opposed to databased. Events are stored in the topics. Currently, the trend is to create smaller applications that can communicate through the Kafka topic. This enables real-time analysis of data stored in topics, instead of batch processing. Writing data from a database into a topic can be done with Kafka connect. This framework is also used to input data from topics to other services. Kafka streams API handles framework and infrastructure to connect/join topics. For database queries Kafka includes kSQL, which outputs into a topic. Kafka cloud enables cloud services with Kafka.
Kafka Fundamentals#
A producer – a service that writes events to the Kafka cluster. A Kafka cluster consists of one or several ** brokers**, with each its local storage. Produces write into these storages. Brokers may be machines, VMs, servers, containers, or similar. To read data from the cluster, we use a consumer. A lot of the work happens on the consume-side of the framework. The consumed data may then be further processed and presented in reports, dashboards or visualizations, ect. Producers and consumers are de-coupled – hence slow consumers will not affect producers and vice versa. Access control, cluster management, and failure detection & recovery is controlled by a leader broker node ( previously Zookeeper).
A topic is a collection of related messages or events – a log or sequence of events. In theory, you can have an unlimited number of topics. Within a topic, we find one or several partitions corresponding to a log, which are allocated to different brokers in the cluster. You can think of partitions as a log; strictly ordered with each message recieving an incremental ID called offset. Within a partitions, we have individual segments, existing on the disk. Kafka performs distributions of the topics to brokers, but the user needs to set resource limitations and requests.
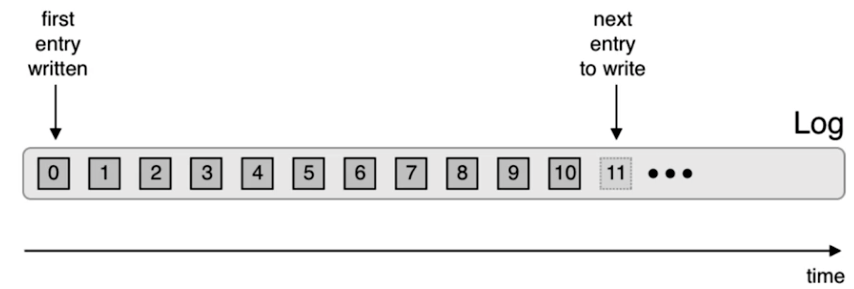
Fig. 1 A representation of a log in Kafka.#
A log consists of several events which contitutes a stream. Each Kafka message consists of a key and value, with an optional header and a timestamp (creation/ingestion time).
Brokers and Clusters#
A Kafka cluster consists of one or several brokers, where one broker is the selected controller. Basic function: manage partitions locally. Takes input from producers and places them in partitions. Recieves requests from consumers and let them read from partitions. Each partition has replicas (controller by replication factor), such that partitions are replicated on separate brokers working as a backup. Also in charge of electing a leader. Partitions are distributed evenly amount available brokers.
Leadership and Replication within a Partition#
When multiple partitions of the same topic are created, one act as the leader and the remaining as followers. The leader is telling producers and consumers that they should be written to, and similarly the consuming comes from this partition. When a broker crashes and contains a leader, a new leader is elected right away, with no loss of data, known as leader election.
In this case, only replicas that are in sync with the leader can be chosen as leaders; they are in-sync replicas ( ISR). If no ISR is available, producers will pause producing. Alternative, a configuration settings known as ** unclean leader election** can be set, which elects a new leder even if no ISR is available.
Replicas in Kafka#
Each topic may have multiple replicas. Replicas are distributed between brokers and provide guarantees for the
availability of data. The amount of replicas is controller by the replication factor, set by the
flag --replication-factor N. Give a replication factor of 3, there will be 3 copies of each partition spread accross
the brokers.Main goals of replicas:
Spread evenly amoung brokers
Each partition is on a different broker
Put replicas on different “racks” – where a broker can be located
A default replication factor is controlled by the variable default.replication.factor=N in server.properties.
Handling Requests#
Between the Producer/Consumer and the Broker there is a request workflow. This includes an acceptor thread, processor thread, IO thread, request queue, and response queue. A request queue, is a request waiting to be processesd. Similarly, a repsonse queue is all requests waiting for being “picked up” by the processor thread/network thread. The IO thread is also known as the request handler thread. A produce request happens from Producer side, and fetch request happens from Replicas and Consumer side. Both requests go through the leader of the replicas; and requires a leader to be present. Each broker has a metadata list; a cache with all paritions and replicas allowing the client to figure out where the leader is.
If acks=all; request is stored in buffer known as purgatory – until data is written to all replicas. This is a *
zero copy* method, no duplication. A minumum number of messages can also be set to avoid small batches.
Partitions in Kafka#
Partitions within a topic are split between brokers, but partitions will never split up. Messages are appended to a
partition, never removed. Partitions are stored under log.dirs. Within a partition in log.dirs, additional files
exist; .log – the message, .checkpoint – to handle (leader) failures, .snapshot – internal Kafka snapshots.
Remaining files are mappings between message offset and physical location.
Tough concepts of Kafka#
Main misconception: “Kafka is a queue”. Instead, Kafka is a log. Second: event streams are immutable. If databases are brief “snapshots” in time, Kafka is a “live broadcast”. Leads to Stream/Table duality; one can be derived by the other. Third: materialized view of database query – using kSQLdb, which updates the data based on the stream.
Why Kafka and log system?#
Fist, consider the existing technology (not stream based): Pros:
Suitable for heavy, complex data transformations and aggregations.
Optimized for high-volume, periodic updates and historical data analysis.
Cons:
Latency issues; not suited for real-time data processing.
Complex and potentially costly ETL (Extract, Transform, Load) processes.
Scalability can be challenging, requiring significant resources.
In contrast, because there is a growing interest in real-time processing of data, we propose the use of logs. Pros:
Enables real-time data processing (ETL) and immediate data availability to multi-subscriber data feeds.
Simplifies data integration across distributed systems.
Enhances system resilience and data recovery through append-only nature.
Logs are at the heart of stream processing; infrastructure for continuous data processing.
Logs act as a buffer allowing processes to be restarted or fail withoyt slowing down other parts of the processing graph.
Data retention#
By default, data is stored for a time of 1 week, but his can be edited either by per topic, or globally. How often the
data is stored depends on the business logic, and GDRP and similar compliance perspectives. When data is expired, it is
purged per segment.
Compacted topics#
The time values are ordered, and the values vary. However, the key may be varying only between key1 to key4 ( example), e.g. 4 unique keys. If previous states are not important, use a compacted topic which removes “old” entries in the partition.
Security#
Kafka will encrypt using SSL or similar all types of transits (producer to broker, broker to consumer, ect.). Kafka also supports authentication and authorization, but using security is optional. However,
Integrating Kafka into you Environment - Kafka Connect#
Kafka can be integrated with any system; through Kafka Connect API – a data integration framework to get data in and out of Kafka. Connect runs on a separate server, between the source and the Kafka cluster. Similarly, betwene the Kafka cluster and the sink. Lots of these connectors already exists between existing frameworks and Kafka Connect. Connect is a distrituted system with \(n\) workers running one or more tasks. Each task runs with a connector, which can again be partitioned into multiple pieces. Connectors can thus be split between multiple workers.
Schema evolution - Schemas#
This can be solved using a Schema Registry; a type descrition will translate into a expected field for each Kafka topics. A schema registry works outside the Kafka Cluster, and are kepy in an internal topic in the Kafka cluster, communicating with the Producer and Consumer. Consumer can ask for schema though a schema ID, to recognize the data format.
Avro: a container file which consists of a metadata (schema) part and a data part, where the schema syntax is
similar to json.
Confluent ksqlDB - KSQL#
Streaming SQL enging for Kafka using SQL-like semantics. Example use cases include streaming ETL, anomaly detection and event monitoring. The system can be accessed via CLI, REST or headless using any programming language.
Kafka Streams#
Kafka Streams is a Java API for doing stream processing on data in Apache Kafka. This combines the streams for Java with
the Kafka, particularly usefull for microservices and continous queries and transformations. Kafka streams live together
with your code within an app instance, which communicates with the Kafka cluster. Streams include functions such
as filter, map, join, and aggregate, working on individual Kafka logs.
The Confluent Platform#
Confluent platform/cloud uses RBAC for authorization with pre-defined role bindings, working accross the platform. This includes kSQL, Connect, Schema Registry, Connectors, ect. Confluent Operator for Kubernetes runs on any plotform at any scale, while also using and manages persistent volumes in K8s. Note, there are hundreds of connectors available for all types of data.